Pongo la mano en el fuego que durante tu vida como programador has tenido que pelearte con las CORS alguna vez, verdad?
Si ya lo has hecho sabrás lo importantes que son y el por culo que dan, pero en cambio, si ni siquiera te suena este término pues… enhorabuena supongo.
Si no lo conoces y te dedicas al desarrollo web es algo que vas a necesitar saber en futuro así que dale.
Eso si, como siempre digo, en mi experiencia como desarrollador lo que mas me ha costado siempre es esto y las expresiones regulares. Esa cosas que se te atasca y no hay manera. Pues eso.
Pero no te preocupes si vas de nuevo porque conociendo los fundamentos de las CORS y a la mínima que hayas resuelto 3 errores de este tipo, te saldrán como churros 😉
¿Qué son las CORS?
A ver, para empezar la palabra CORS es una sigla de Cross-Origin Resource Sharing. Esto es, traducido al castellano Intercambio de recursos de Origen Cruzado.
Pero no nos dice mucho. Vayamos a la wikipedia y a partir de ahí desarrollamos.
Intercambio de recursos de origen cruzado o CORS es un mecanismo que permite que recursos restringidos (como por ejemplo, las tipografías) de una página web puedan ser solicitados desde un dominio diferente por fuera desde el cual el primer recurso fue expuesto.
CORS define una forma en la cual el navegador y el servidor pueden interactuar para determinar si es seguro permitir una petición de origen cruzado. Esto permite tener más libertad y funcionalidad que las peticiones de mismo origen, pero es adicionalmente más seguro que simplemente permitir todas las peticiones de origen cruzado.
Creo que se entiende bastante bien pero para resumir consiste en que una página «no puede» cargar datos o elementos de otra página diferente.
Y pongo entre comillas «no puede» porque precisamente las CORS definen una política de seguridad que nos permite jugar con los recursos.
Obviamente todo esto tiene que ver con el desarrollo de páginas web y/o aplicaciones web. A la mínima que te pongas a hacer algo para la web vas a utilizar javascript si o si y lo sabes.

Y en el fondo también tirarás de Ajax. Y si no piensa en todos los frameworks de front como funcionan en su base. Peticiones Ajax una y otra vez.
Pero antes de que apareciera el protocolo de las CORS no se podían cargar datos por Ajax en una página A desde otra página B.
Me explico.
Desde gorkamu.com yo no podía acceder a los recursos de forocoches.com, por ejemplo. Sólo se podía acceder a los recursos que estuvieran alojados bajo un mismo dominio. Es decir:
- gorkamu.com/css/styles.css
- gorkamu.com/js/form.js
¿Se entiende no?
Pues eso, que no se podía.
Aunque realmente había formas para «saltarse» esta limitación utilizando JSONP pero no eran genéricas desde luego…
¿Cómo funcionan las CORS?
Vale ahora pongámonos técnicos porque vamos a entrar con el tema del preflight y cómo afectan a las CORS.
Cuando una página web intenta conectar con otra para acceder a un recurso, ahí se está produciendo una petición HTTP. Las hay de distintos tipos pero todas ellas llevan cabeceras en su petición.
Aquí te explico un poco mas en detalle qué es y cómo funciona el protocolo HTTP.
Pues justo antes de que se llegue a realizarse la petición tu navegador automáticamente la intercepta para enviar antes el una primero.
Esta pre-petición automática es conocida porque se ejecuta bajo el método OPTIONS y no tiene cuerpo, sólo envía las cabeceras.
Las cabeceras o headers que se envían por parte del navegador le dan información al servidor sobre qué quiere hacer.
Así pues, en función de lo que nos responda el servidor después de esta primera pre-llamada, la petición original podrá continuar o por el contrario se bloqueará y arrojará un error.

Fíjate bien porque tal y como ves, este error de CORS también se produce por intentar acceder a un puerto diferente del 80 o 443. Aunque formen parte del mismo dominio.
Imagínate que abres Google Drive y haces una petición cualquiera. Por ejemplo el guardar un documento nuevo.
Si inspeccionas desde las herramientas para desarrolladores de tu navegador podrás ver algo tal que así:

Esto que ves es la pantalla en la que puedes comprobar las peticiones HTTP que se están produciendo para esa página. Aquí puedes ir viendo una por una de qué tipo es y qué datos envía o recibe.
En la parte de Request Headers vemos las cabeceras que se han enviado en el preflight de la petición original. Hay varias de ellas pero quédate con las siguientes:
-
access-control-request-headers: authorization, x-goog-authuser
-
access-control-request-method: POST
- origin: https://drive.google.com
La primera cabecera, access-control-request-headers, es una cabecera que se envía durante el proceso de preflight y le permite saber al servidor qué otras cabeceras HTTP van a usarse cuando se realice la petición. En el ejemplo se utilizan dos: authorization para autenticarse bajo Bearer o oAuth lo mas probable y la segunda x-goog-authuser para autenticarse contra Google.
La cabecera access-control-request-method le indica al servidor que métodos o acciones puede llegar a hacer la petición. En el ejemplo indica que solo va a ejecutar un método POST pero se pueden añadir tantas igual como de verbosa sea la API a la que quiere acceder.
La última cabecera, origin, le dice al servidor desde donde se realiza la petición. Si este host es válido para el servidor permitirá realizar la petición. Si por el contrario no reconoce el valor de la cabecera origin echará para atrás la request.
Ahora bien, si el servidor reconoce y valida estas cabeceras de la petición preflight podrá ejecutarse la petición original, sino no.
¿Pero y qué es lo nos responde el servidor?
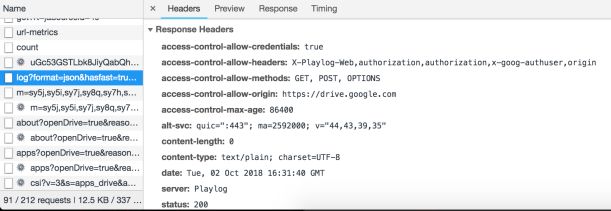
Aquí las cabeceras de respuesta. Fíjate que devuelve con las mismas que hemos visto pero con alguno de sus valores ampliado. Por ejemplo la cabecera access-control-request-method, que a diferencia de lo que se enviaba en la petición, nos responde que acepta los métodos GET, POST y OPTION.
Esto es, para toda la aplicación los únicos métodos que pueda ejecutar cualquier petición serán esos tres únicamente. En el caso de que fuera una API a lo que se consulta, no sería muy verbosa si la entendemos como una RESTFull API…
¿Cómo habilitar las CORS?
Si ya has entendido como funciona esta política y ves el potencial que tiene probablemente quieras empezar a usarla ya.
Antes de nada piensa que si tu perfil es puramente backend estás de enhorabuena ya que la película de habilitar las CORS en tu API va a caer de tu parte si o si.
El gran trabajo lo tienes que hacer tu.
Y por parte de la gente de front tan solo hay que añadir las cabeceras a las peticiones y del resto ya se encarga el navegador (y el programador backend 😂)
Existe una página de referencia para saber cómo habilitar las CORS en diferentes tecnologías. La web en cuestión es esta, ya puedes guardártela bien en los marcadores…
Utilizar CORS en Apache
Apache, uno de los servidores mas utilizados en el mundo web. Aquí tienes un ejemplo de cómo usar esta política con este servidor.
Para añadir la autorización CORS a las cabeceras de Apache tan solo añade la siguiente línea dentro de la etiqueta <Directory>, <Location>, <Files> o <VirtualHost> de tu configuración
Header set Access-Control-Allow-Origin "*"
Esta línea lo que hace es permitir las conexiones desde todos los orígenes. También puedes añadirla en tu .htaccess
Para asegurarte de que se ha aplicado correctamente la configuración puedes comprobarlo tirando la siguiente línea en la consola:
apachectl -t
Una vez que la veas aplicada tan solo te tocará reiniciar el servidor y listo!
sudo service apache2 reload
Añadir las CORS en NGINX
Para el que no lo conozca Nginx es otro servidor web bastante utilizado. Aunque también podemos configurarlo para ser utilizado como un Proxy-Inverso o como un balanceador de carga entre otras cosas.
Últimamente en mis desarrollos lo estoy utilizando mas que Apache incluso. Para habilitar las CORS en Nginx tienes a continuación la configuración necesaria.
#
# Wide-open CORS config for nginx
#
location / {
if ($request_method = 'OPTIONS') {
add_header 'Access-Control-Allow-Origin' '*';
add_header 'Access-Control-Allow-Methods' 'GET, POST, OPTIONS';
#
# Custom headers and headers various browsers *should* be OK with but aren't
#
add_header 'Access-Control-Allow-Headers' 'DNT,User-Agent,X-Requested-With,If-Modified-Since,Cache-Control,Content-Type,Range';
#
# Tell client that this pre-flight info is valid for 20 days
#
add_header 'Access-Control-Max-Age' 1728000;
add_header 'Content-Type' 'text/plain; charset=utf-8';
add_header 'Content-Length' 0;
return 204;
}
if ($request_method = 'POST') {
add_header 'Access-Control-Allow-Origin' '*';
add_header 'Access-Control-Allow-Methods' 'GET, POST, OPTIONS';
add_header 'Access-Control-Allow-Headers' 'DNT,User-Agent,X-Requested-With,If-Modified-Since,Cache-Control,Content-Type,Range';
add_header 'Access-Control-Expose-Headers' 'Content-Length,Content-Range';
}
if ($request_method = 'GET') {
add_header 'Access-Control-Allow-Origin' '*';
add_header 'Access-Control-Allow-Methods' 'GET, POST, OPTIONS';
add_header 'Access-Control-Allow-Headers' 'DNT,User-Agent,X-Requested-With,If-Modified-Since,Cache-Control,Content-Type,Range';
add_header 'Access-Control-Expose-Headers' 'Content-Length,Content-Range';
}
}
Habilitar las CORS en PHP
Como bien he dicho mas arriba, Apache es uno de los servidores web mas utilizado y es por supuesto el servidor por excelencia para el lenguaje PHP.
De hecho un stack típico es el de LAMP, MAMP o WAMP que no deja de ser otra cosa que Linux o MacOS o Windows junto con Apache, Mysql y PHP por sus siglas….
Si por un casual no tienes acceso a editar la configuración de Apache siempre puedes habilitar las CORS en PHP añadiendo la siguiente cabecera:
<?php
header("Access-Control-Allow-Origin: *");
Esta cabecera la tendrás que poner antes de cualquier función que devuelva una respuesta.
Usar CORS con Express
El último de los ejemplos es habilitar esta política con Express. Un framework Javascript super utilizado principalmente para el desarrollo de APIs. Todo corriendo bajo Node claro está!
app.use(function(req, res, next) {
res.header("Access-Control-Allow-Origin", "*");
res.header("Access-Control-Allow-Headers", "Origin, X-Requested-With, Content-Type, Accept");
next();
});
Con esto llegamos al final del artículo.
Espero que te haya quedado claro. A mi al principio me costó entenderlo y me tiraba de los pelos cada vez que me salía un error de estos al realizar una petición a través de Ajax a un recurso externo…
Pero no te preocupes, al segundo error que te salga de este tipo ya sabrás solucionarlo y sino siempre puedes preguntarme a través de twittah.
[xyz-ips snippet=»FAQS-GORKAMU-TW-YELLOW»]
A pastar!







Debe estar conectado para enviar un comentario.